Take the Rough With the Smooth
The starting point of the previous post was optimization of differentiable functions, but trying to utilize Fermat's theorem led us eventually to bracketing algorithms, which make no use of the derivative and are applicable for non-differentiable functions.
That's good, but not as good as it sounds. Firstly, non-smooth optimization is very nice - but often the objective of interest is known to be smooth. Reasonably then, taking it into account should improve convergence rate. Secondly, those bracketing algorithms work on univariate objectives. In practice, objectives are usually multivariate - and while adapting bracketing to the multivariate setting is possible, gradient and sub-gradient based methods are often superior in this respect.
This post explores strategies for incorporating derivatives in optimization algorithms, in hope it would lead to improved algorithms. The objective functions are still assumed to be univariate, but it does not render those method pointless. The transition to multivariate objective functions (starting in the next post) will leverage ideas and reuse algorithms from those two posts about univariate functions.
Content
- When smooth-optimization doesn’t go smoothly
- Bracketing with Gradients - Take 1: Modified Brent’s Method
- Roots without Bracketing: Newton’s Method
- Bracketing with Gradients - Take 2: Hybrid Newton Method
- Multivariate Objectives: A Preview
1. When smooth-optimization doesn’t go smoothly
Let's begin with lowering expectation.
Sure, computationally, computing $f$ and $\nabla f$ is equally hard; and yes, theoretically it is indeed possible to accelerate convergence using derivatives. But while it is indeed reasonable to think that an explicit exploitation of smoothness would increase convergence rate, things are actually trickier than that.
Firstly, as we've seen before, in strategies that rely on Fermat's theorem computing just $\nabla f$ is not enough for distinguishing minima from maxima; and a computation of both $f$ and $\nabla f$ pretty much amounts to doubling the computation effort at each step.
Without somehow overcoming this issue, by either efficient approximations or some cleverly reused computations, or by giving up on using Fermat's theorem (for example, as the gradient decent method - to be discussed in an upcoming post - does) using gradients and Hessians is not such a great idea after all.
Secondly, optimization algorithms that do use derivatives are often sensitive to their precision. Obviously, getting the wrong signs of the gradient due to numerical errors does not help anyone's mood, but even less blunt approximation and truncation errors may lead the optimization process astray. For example, the gradient decent method I was just mentioning takes the gradient as the direction of the maximal decent of the objective, which means that in naive implementations even a slightly inaccurate gradients may lead the algorithm to a completely wrong direction.
The same issue may show up in different forms. Notably when using polynomial approximations for the objective. Such ideas are to large extent the basis for second-order line-search algorithms (e.g. quasi-Newton methods), and even more-so with regard to trust-region methods (again, future posts will cover both).
As an demonstration for the potential problem, consider the idea of optimization via polynomial interpolation, e.g. by fitting a polynomial using some high-order derivatives of the objective, and use its optima as an approximation for the target optima. There are actually efficient schemes for doing so by reusing calculated values and minimize function evaluations, so all-in-all the strategy seems plausible.
Yet, polynomials are numerically wild. They are wiggly, and their general shape tends to be ill-conditioned with respect to their coefficients. For example (admittedly, a toyetic one), if locally, near an approximated maximum, the objecive looks like this:
In [1]:
x=np.linspace(-5, +5, 100); plt.plot(x, 1/(1+np.square(x)))Out [1]:
Then fitting a polynomial, could look like this:
In [2]:
x1=np.linspace(-5, +5, 100); x2=np.linspace(-5, +5, 16); plt.plot(x1, scipy.interpolate.BarycentricInterpolator(x2, 1/(1+np.square(x2)))(x1))Out [2]:
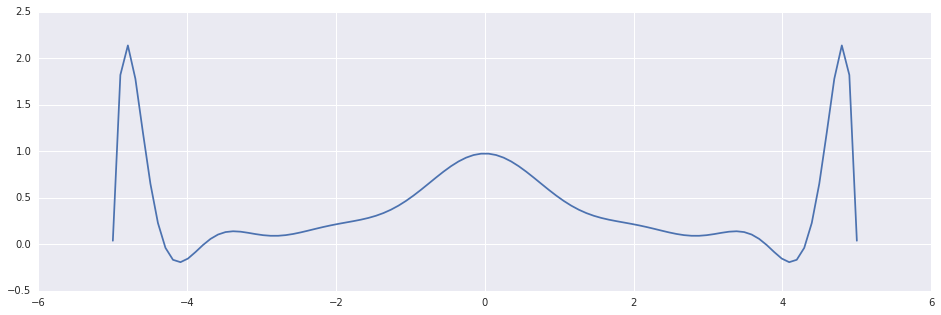
This could be very harmful: most of the effort in solving an optimization problem is invested in getting "close enough" to the optimum. The potential cost of getting thrown away far from the solution may be much higher than the benefits of a possible slightly improved convergence rate.
2. Bracketing with Gradients - Take 1: Modified Brent’s Method
Dispite the warnings above, there is a useful way to use derivatives in bracketing algorithms. The trick is to to ignore their values, and use only their signs. This makes the algorithm robust under badly approximated gradients, and computationally efficient, since the gradient can be computed only very roughly.
As a matter of fact, this "trick" is common enough in the context of numerical optimization to deserve a promotion to a "technique" (especially in the context of stochastic gradient descent, but that's a whole nother story, to be told in due time).
Let's use this trick in conjunction with the latest bracketing method from the last post, namely Brent's method. This is essentially the same algorithm, but now the sign of the first derivative is used the decide which of the two triplet's sub-intervals is likely to contain the minimum.
In [3]:
def default_tolerance(x1, x2):
return np.finfo(np.float64).eps*(abs(x1)+abs(x2))*0.5
def modified_brent(f, ftag, triplet, tolerance=None, maxiters=50):
golden = scipy.constants.golden - 1.0
triplet = [triplet[0], triplet[1], triplet[2]]
values = [f(triplet[0]), f(triplet[1]), f(triplet[2])]
gradients = [ftag(triplet[0]), ftag(triplet[1]), ftag(triplet[2])]
assert(values[1] < min(values[0], values[2]))
ref_step = 0.0
if tolerance is None:
tolerance = default_tolerance(triplet[0], triplet[2])
def interpolation_step():
A = triplet[1]-triplet[0]
B = triplet[1]-triplet[2]
C = values[1]-values[2]
D = values[1]-values[0]
X = A*C
Y = B*D
step = -0.5*(A*X-B*Y)/(X-Y)
return triplet[1]+step, step
def golden_section_step():
if (triplet[1]-triplet[0]) > (triplet[2]-triplet[1]):
step = golden*(triplet[1]-triplet[0])
return triplet[0]+step, step
else:
step = golden*(triplet[2]-triplet[1])
return triplet[1]+step, step
for i in xrange(maxiters):
if (triplet[2]-triplet[0]) < tolerance*np.abs(values[1]):
return triplet[1], i
if np.abs(ref_step) > tolerance*np.abs(triplet[1])+1e-10:
x, ref_step = interpolation_step()
y = f(x)
else:
x, ref_step = golden_section_step()
y = f(x)
if y < values[1]:
if x > triplet[1]:
triplet = [triplet[1], x, triplet[2]]
values = [values[1], y, values[2]]
else:
triplet = [triplet[0], x, triplet[1]]
values = [values[0], y, values[1]]
else:
if x > triplet[1]:
triplet = [triplet[0], triplet[1], x]
values = [values[0], values[1], y]
else:
triplet = [x, triplet[1], triplet[2]]
values = [y, values[1], values[2]]
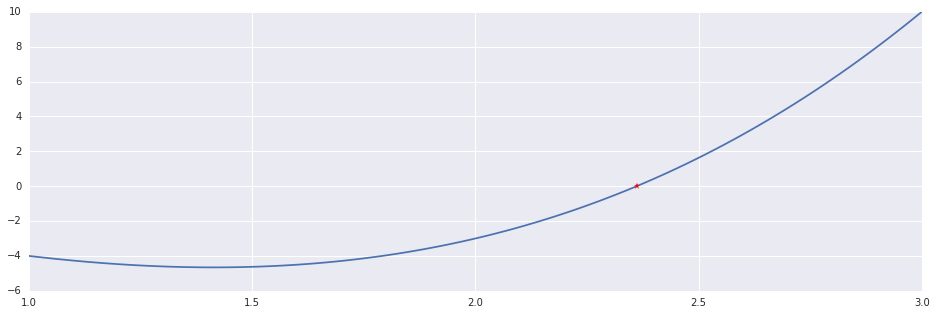
return triplet[1], maxitersThe arbitrary running example in this post will be the function $f(x)=x^3-6x+1$ in the interval $[1, 3]$:
In [4]:
f = lambda x: x**3-6*x+1
ftag = differentiate(f, 0.00001)
interval = np.linspace(1.0, 3.0, 100)And here's Modified Brent's method in action:
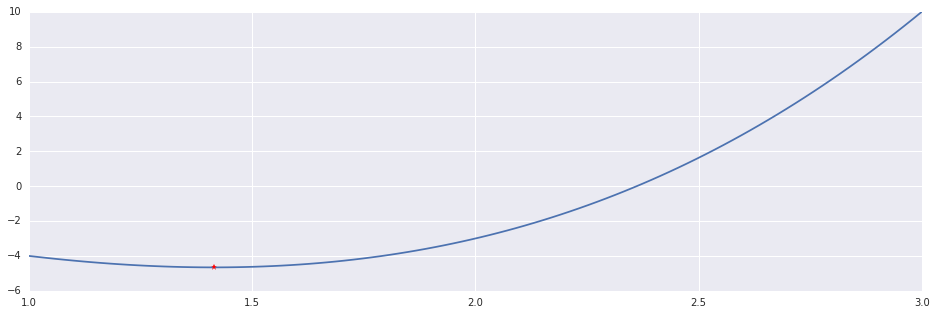
In [5]:
x, n = modified_brent(f, ftag, (1.0, 1.5, 3.0))
print "Modified Brent's Method: %d Iterations."%n
plt.plot(interval, f(interval))
plt.plot((x,), (f(x),), 'r*')Out [5]:
Modified Brent's Method: 50 Iterations.
3. Roots without Bracketing: Newton’s Method
Say you're given a differentiable function $F$ whose roots you'd like to find. Also, say you're name is Newton. So using Taylor series, you obtain $F(x+\delta) = F(x) + J(x)\delta + O(\delta^2)$, and note that if you choose $\delta_0$ such that $J(x)\delta_0 = -F(x)$, then you get $F(x+\delta_0) = O(\delta_0^2)$.
This suggests the iterative scheme $x_{n+1} = x_n + \Delta_n$ where $\Delta_n$ is the solution to the linear system $J(x_n)\Delta_n = -F(x_n)$, which can be reasonably expected to converge to a point $x_0$ such that $F(x_0)=0$ (and it provably does, with some standard fine prints regarding regularity and the goodness of the initial point).
This is Newton's root-finding method:
In [6]:
### Univariate Root-Finding with Newton
def newton_roots(f, df, interval, tolerance=None, max_iters=50):
x = interval[0] + (interval[1]-interval[0])*0.5
y = f(x)
if tolerance is None:
tolerance = default_tolerance(x, x)
for i in xrange(max_iters):
if abs(y) < tolerance:
return x, i
x = x - y / df(x)
y = f(x)
return x, max_itersI think that Newton's method sheds light on the point that opened the previous post: as a root-finding method, Newton's method is effective mainly because it's actually an optimization algorithm in heart, that alternates maximization and minimization steps (i.g. finding roots of $F$ is the same as minimizing $||F||$).
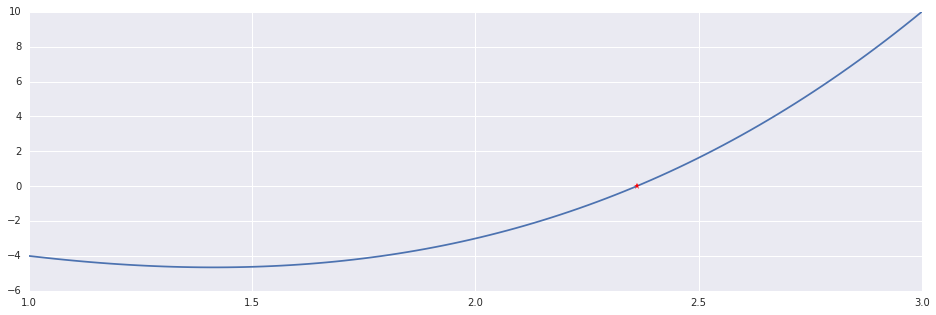
In [7]:
x, n = newton_roots(f, ftag, (1.0, 3.0))
print "Newton's Method: %d Iterations."%n
print '\t Result: ', x, np.isclose(f(x), 0.0)
plt.plot(interval, f(interval))
plt.plot((x,), (f(x),), 'r*')Out [7]:
Newton's Method: 6 Iterations.
Result: 2.36146876619 True
4. Bracketing with Gradients - Take 2: Hybrid Newton Method
The algorithm that was just presented may find a point outside of the given interval. This is a manifestation of a general problem with the algorithm: there's not guarantee that the iterations monotonically bring us closer to a root (i.e. it's not a "descent method").
A way to mitigate the issue is by combining Newton's method with bracketing: as usual, the algorithm maintains a bracket $(a, b)$ such that $f(a)$ and $f(b)$ have opposite signs, and at each iteration updates one of the endpoints using a Newton step. If it so happens and the step takes the algorithm outside of the current interval, the algorithm reverts to the bisection method. This combination (which comes in several variations) is usually referred to as "Hybrid Newton Method":
In [8]:
def hybrid_newton_roots(f, df, interval, tolerance=None, max_iters=50):
x0, x1 = interval[0], interval[-1]
y0, y1 = f(x0), f(x1)
if y0 > 0:
x0, x1, y0, y1 = x1, x0, y1, y0
assert(y0 < 0)
assert(y1 > 0)
if tolerance is None:
tolerance = default_tolerance(x0, x1)
for i in xrange(max_iters):
x_curr, y_curr = x1, y1
if abs(y0) < abs(y1):
x_curr, y_curr = x0, y0
if abs(y_curr) < tolerance:
return x_curr, i
x_next = x_curr - y_curr / df(x_curr)
if (x_next < np.min((x0, x1))) or (x_next > np.max((x0, x1))):
x_next = x0 + (x1-x0)*0.5
y_next = f(x_next)
if np.sign(y_next) == np.sign(y0):
x0, y0 = x_next, y_next
else:
x1, y1 = x_next, y_next
return x_curr, max_itersIn [9]:
x, n = hybrid_newton_roots(f, ftag, (1.0, 3.0))
print "Hybrid Newton: %d Iterations."%n
print '\t Result: ', x, np.isclose(f(x), 0.0)
plt.plot(interval, f(interval))
plt.plot((x,), (f(x),), 'r*')Out [9]:
Hybrid Newton: 7 Iterations.
Result: 2.36146876619 True
5. Multivariate Objectives: A Preview
You might have noted that the entire discussion about the Newton's method and the Hybrid Newton Method has framed the methods as root-finding algorithms, and not as optimization algorithms. Of course, one of the central points of the current and the previous post was to relate the two concepts. But I opted to deffer the adaptation of those methods for optimization to the next post.
That's because as the notation I've used above may already hinted, unlike all the methods discussed so far, Newton's method can be readily used for multivariate functions $F:R^n\rightarrow R^m$ and be made into a multivariate optimization algorithm. But using this method as-is for this purpose is impractical (due to both numerical and computational reasons). Fortunately, there are effective and practical modifications of it.
The next post will start exploring this landscape.