The Name of The Rose
Many ideas in machine learning came up independently in different contexts, and it's not uncommon to have multiple terms for the same concept. Those instances are usually dismissed as nuisance; after all, a rose by any other name, et cetera. Indeed, often this is just a matter of nomenclature, and with time conventions form, and some terms disappear while others acquire universal meaning. But sometimes the distinction is not as superficial as it may seem.
Recently I encountered such a situation, in which while explaining someone a term I used, it became clear that this person was already familiar with the concept under a different name. But what initially looked like nothing more than a confusing lingo, turned out to be of fundamental significance.
An engineer, a statistician and an algorithmician walk into a bar…
Noise Cancellation
An electrical engineer is facing the task of building an active noise-canceller for cellular phones: a device that transmits the speaker's voice while omitting the environmental noise. This can be done using an additional directional microphone to record the environment, and a filter that subtracts it from the recordings of the main microphone used to record the speaker.
Since the filter's transfer function should vary in time, in response to the unpredictable environmental noise, an adaptive filter is required. The simplest such filter is the so-called "least mean squares" (LMS) filter. Here's its block diagram (taken from Wikipedia):
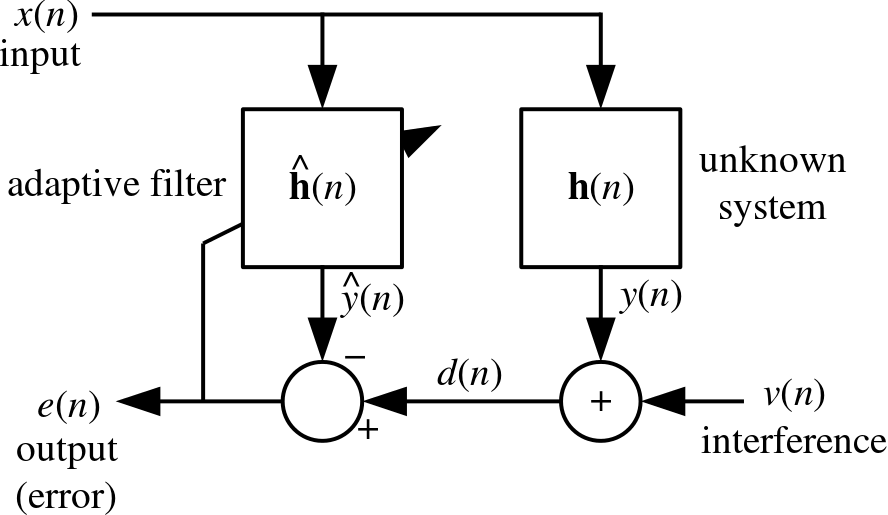
Naively implementing it in software is straightforward:
In [1]:
def lms_step(curr_weights, Xt, yt, step_size):
yest = curr_weights.dot(numpy.squeeze(Xt))
next_weights = curr_weights + (step_size * (yt - yest) / Xt.dot(Xt)) * Xt
return yest, next_weights
def lms(initial_weights, X, y, step_size):
y_lms = numpy.zeros(len(y))
weights = initial_weights
for i in xrange(len(y)):
y_lms[i], weights = lms_step(weights, X[i, :], y[i], step_size)
return y_lmsIn the context of noise cancellation, the engineer applies it backwards, by using the noise signal $r_1(t)$ to remove the speech-signal $v(t)$ from the noisy speech-signal $v(t)+r_2(t)$ (note that $r_1(t)\approx r_2(t)$, but they are not equal since they were recorded using different microphones in different locations).
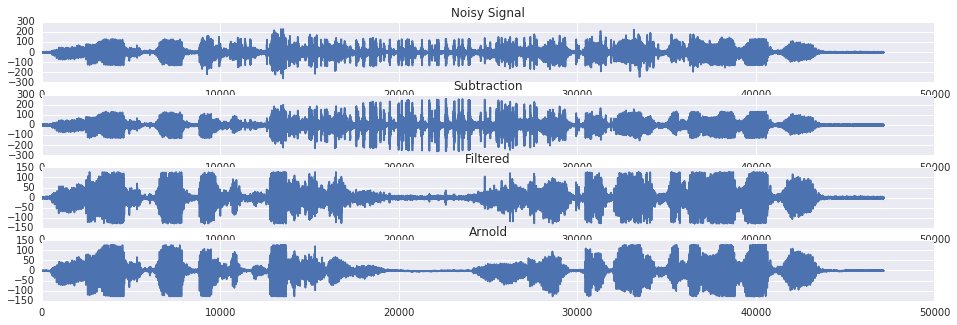
As a demonstration, consider the canonical example of Arnold Schwarzenegger trying to make a phone call while watching a bear riding a motorcycle:
| Noisy: | |
| Filtered: |
In [2]:
voice, voice_params = read_wave('files/questions.wav')
noise, noise_params = read_wave('files/applause.wav')
diff = (len(voice)-len(noise))/2.0
noise = numpy.pad(noise, (int(numpy.ceil(diff)),int(numpy.floor(diff))),
'constant', constant_values=(0, 0))
noisy_voice = voice + noise + numpy.random.normal(0.0, numpy.std(noise)/10.0, len(noise))
distortion_factor = numpy.sin(numpy.linspace(0, 10, len(noise)))
noise_input = distortion_factor*noise + numpy.random.normal(0.0, numpy.std(noise)/10.0, len(noise))
filtered = noisy_voice - lms(numpy.array([0, 0]),
numpy.vstack([noise_input, numpy.ones(len(noise_input))]).T,
noisy_voice, 0.05)
plt.subplot(4,1,1)
plt.title('Noisy Signal')
plt.plot(noisy_voice)
plt.subplot(4,1,2)
plt.title('Subtraction')
plt.plot(noisy_voice-noise_input)
plt.subplot(4,1,3)
plt.title('Filtered')
plt.plot(filtered.astype(numpy.int8))
plt.subplot(4,1,4)
plt.title('Arnold')
plt.plot(voice)Out [2]:
Vehicle Routing
A statistician is hired by a retail company for the task of minimizing delivery times from their warehouse to their stores. There are multiple routes between the warehouse and any of the stores, and the traffic in those routes erratically changes during the day. For simplicity, let's focus on the case of 1 store with 2 possible routes.
There is some potentially useful information available, such as reports from navigation applications (e.g. Waze) and a-priori estimations of the current traffic based on the time (e.g. the notorious traffic jams of Wednesday mornings) - but it's not clear how to factor it into a decision, due to the instability of the traffic patterns. For example, sometimes traffic jams tend to clear up quickly and current reports should carry little weight relative to the day and time, and sometimes they're persistent and reports should be taken very seriously.
This hints towards online learning: constantly updating the decision rule based on its recent performance. The perceptron is the simplest online classification algorithm. It is very roughly modeled after a biological single neuron (the McCulloch–Pitts model). It may either "fire" or "hold", and the decision is based on whether its weighted accumulated input is crossing a threshold. Schematically:
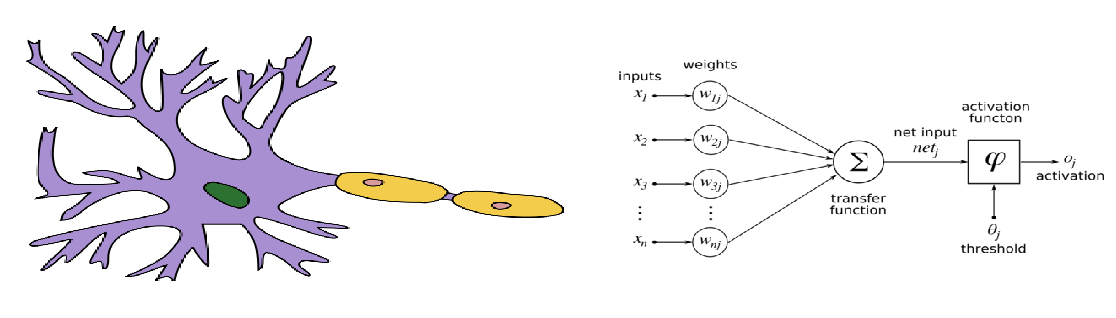
The weights are learnt in a supervised manner using an algorithm known as "the perceptron's update rule", which is applicable as an online algorithm. The update rule is rather heuristic: if there's no error, keep the weights; otherwise, change the weight of each input in proportion to its magnitude, in the opposite direction of the error. If "fire" is represented by 1 and "hold" by 0, the rule is simply $w_{i,t+1}\leftarrow w_{i,t}+\delta(y_t-\hat{y}_t)x_i$.
In [3]:
def online_perceptron_step(curr_weights, Xt, yt, learning_rate):
yest = 0 if curr_weights.dot(numpy.squeeze(Xt))<0 else 1
next_weights = curr_weights + learning_rate*(yt - yest)*Xt
return yest, next_weights
def online_perceptron(initial_weights, X, y, learning_rate):
y_perceptron = numpy.zeros(len(y), dtype=numpy.ubyte)
weights = initial_weights
for i in xrange(len(y)):
y_perceptron[i], weights = online_perceptron_step(weights, X[i, :], y[i], learning_rate)
return y_perceptronSay the statistician has 4 sources of information: $R_1, R_2 \in[0,1]$ are the current reports regarding route A and route B respectively (0 means the route is clear and 1 means it's jammed), and $A_1, A_2\in[0,1]$ are the current (periodic) time-based estimations of the traffic in the routes:
In [4]:
normalize = lambda x: (x-numpy.min(x))/(numpy.max(x)-numpy.min(x))
A1 = numpy.abs(numpy.sin(numpy.arange(1010)/100.0))
A2 = numpy.abs(numpy.cos(numpy.arange(1010)/100.0))
realA = normalize(A1+numpy.cumsum(numpy.random.normal(0.0, 100.0/numpy.sqrt(1010.0), 1010)))
realB = normalize(A2+numpy.cumsum(numpy.random.normal(0.0, 100.0/numpy.sqrt(1010.0), 1010)))
A1 = A1[:-10]
A2 = A2[:-10]
R1 = normalize(realA[10:] + numpy.random.normal(0.0, 0.5, 1000))
R2 = normalize(realB[10:] + numpy.random.normal(0.0, 0.5, 1000))The decision is going to be based on the difference between the current traffic estimations based on real-time repotrs $R_1-R_2$, and the difference between the current traffic estimations based on the current time and date $A_1-A_2$:
In [5]:
A = A1-A2
R = R1-R2
real_classes = (realA<realB).astype(numpy.ubyte)[:1000]
plt.subplot(2,1,1)
plt.title('Usual Traffic Status (Route A vs. Route B)')
plt.plot(A)
plt.subplot(2,1,2)
plt.title('Real-Time Traffic Reports (Route A vs. Route B)')
plt.plot(R)
plt.tight_layout()Out [5]:
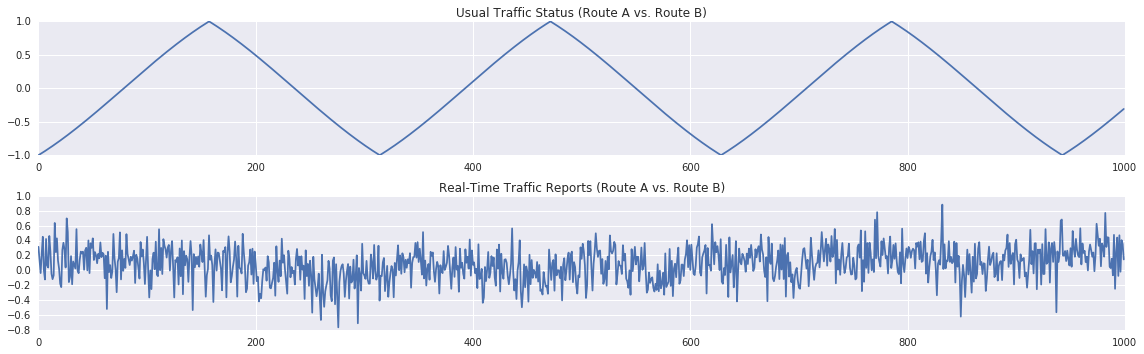
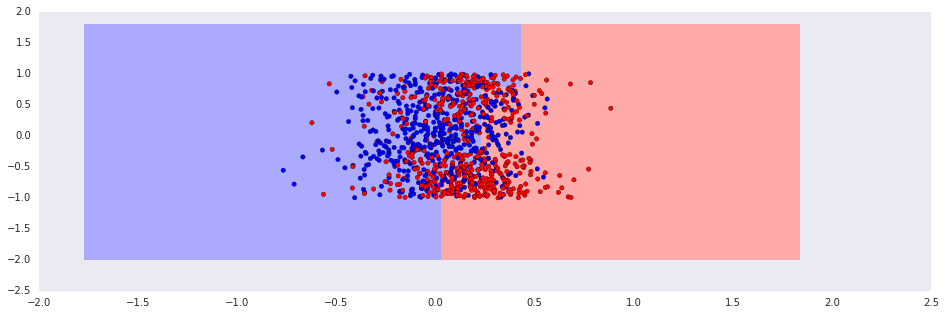
Due to the temporal dynamics, a stationary classifier is unlikely to work, and the classes aren't linearly separable:
In [6]:
classifier = sklearn.linear_model.LogisticRegression(fit_intercept=True)
classifier.fit(numpy.vstack((R, A)).T, real_classes)
plot_decisions(classifier, numpy.vstack((R, A)).T, real_classes, h=0.2, title=None)Out [6]:
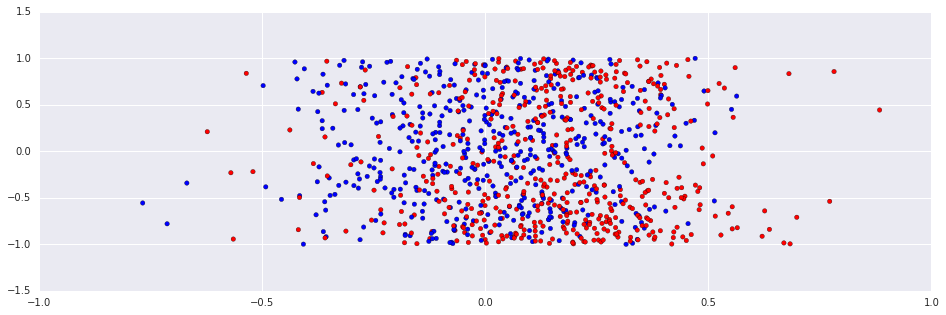
On the other hand, the online learning algorithm is adaptive to the temporal structure, and works rather well:
In [7]:
classes_perceptron = online_perceptron(numpy.zeros(2), numpy.vstack((R, A)).T, real_classes, 0.1)
plt.scatter(R, A, c=classes_perceptron, cmap=ListedColormap(['#FF0000', '#00FF00', '#0000FF']))
print "Accuracy: %.2f."%(numpy.sum(real_classes==classes_perceptron)/(len(classes_perceptron)+0.0))Out [7]:
Accuracy: 0.91.
Online Advertising
A consumer product company starts a new campaign over the internet, and it needs to decide how much it is worth paying for serving its new ad. The decision should take into account the potential viewer demographics (say, age and economic status), and the evaluation must somehow mitigate the fact that the impact of the ads is indirect and delayed: it's impossible to relate a specific sale with a specific viewing of an ad. Moreover, the effectiveness of the ads is likely to vary over time.
An algorithm designer is assigned with the task of writing the engine that interacts with the demand-side platform. The standard framework for constructing a policy that maximizes long-term utilities based on observed immediate rewards is Temporal Differences. In the current simplified setting, the policy should be based on a linear function of an "age signal" $x_t\in[0,1]$ (where 1 means a viewer in his twenties, and 0 means the viewer is either much younger or much older), and a "economic status" signal $y_t\in[0,1]$ (where 1 means "spendthrift").
At each time-step, the engine receives a reward $r_t$, which measures the flow of incomes from sales. Of course, the value of $r_t$ is the noisy result of previous exposure to ads, and has nothing to do with the decision made by the engine at time $t$.
Dealing with (potentially infinite) sequences of rewards leads to the idea of "discounted rewards" (with a discount factor $\gamma$). So the utility at time $t$ is $U(x_t,y_t)=E[\sum\gamma^{i-1}r_{t+i}|(x_t,y_t)]$, and the engine maintains an estimation $\hat{U}_t\approx U$, and iteratively updates it based on his observations.
Discounting can be understood in several ways: it can be derived axiomatically by specifying some reasonable properties of temporal preferences (c.f. Koopmans), or it can be seen as a way to incorporate infinite horizons with random stopping times, or finally, it can be justified economically by considering the usual stories about the risk that is associated with future incomes, or about the "hypothetical losses" of potential profits that could be obtained by investing the said income in the present.
For example, say that in time $t-1$ the engine observed $(x_{t-1},y_{t-1})$, rewarded $r_{t-1}$ and served an ad based on the estimation $\hat{U}_{t-1}(x_{t-1},y_{t-1})=u_0$. Then in time $t$ it observed $(x_t,y_t)$, and experienced an immediate reward $r_t$. So one option the engine may employ, is to update $\hat{U}_{t}(x_{t-1},y_{t-1})=\alpha(r_t+\gamma\hat{U}_{t-1}(x_t,y_ t)-\hat{U}_{t-1}(x_{t-1},y_{t-1}))$ and $\hat{U}_{t}(x,y)=\hat{U}_{t-1}(x,y)$ for $(x,y)\neq (x_t,y_t)$ (where $\alpha$ is the learning rate).
This is knowns as $\mathrm{TD}{(0)}$ rule, and it's a special case of the $\mathrm{TD}(\lambda)$ algorithm which I won't discuss here ("TD" stands for temporal differences). In this case, $\hat{U}_t(x,y)=\omega_1x+\omega_2y$, so the update rule should be applied to update the weights $(\omega_1,\omega_2)$. This can be naturally done by $\omega_1\leftarrow\omega_1+\alpha (r_t+\gamma\hat{U}_{t-1}(x_t,y_t)-\hat{U}_{t-1}(x_{t-1},y_{t-1})) x$ (and the same applies for $\omega_2$).
Here a simulation of the situation described above:
In [8]:
def execute_engine(count):
age = numpy.random.uniform(0, 1, count)
economic = numpy.random.uniform(0, 1, count)
scores = (age+3.0*economic)/4.0
delays = numpy.random.geometric(0.6, count)
values = numpy.random.normal(scores, 0.05, count)
rewards = numpy.zeros(count)
for i in xrange(count):
rewards[min(i+delays[i], count-1)] += values[i]
states = numpy.vstack((age, economic, numpy.ones(count))).T
return states, rewards
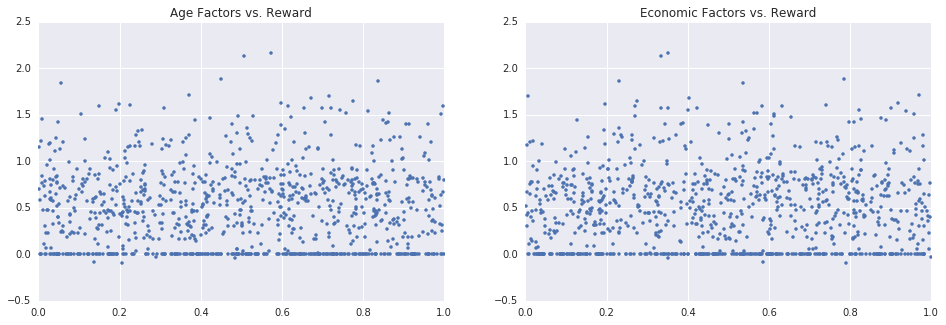
states, rewards = execute_engine(20000)Since the profits from an ad are both delayed and stochastic, at any given time there will be no relation between the current user, and the current reward - which makes it hard (impossible?) to learn a good decision rule by using supervised learning algorithms:
In [9]:
plt.subplot(1,2,1)
plt.title('Age Factors vs. Reward')
plt.plot(states[-1000:, 0], rewards[-1000:], '.')
plt.subplot(1,2,2)
plt.title('Economic Factors vs. Reward')
plt.plot(states[-1000:, 1], rewards[-1000:], '.')
plt.show()
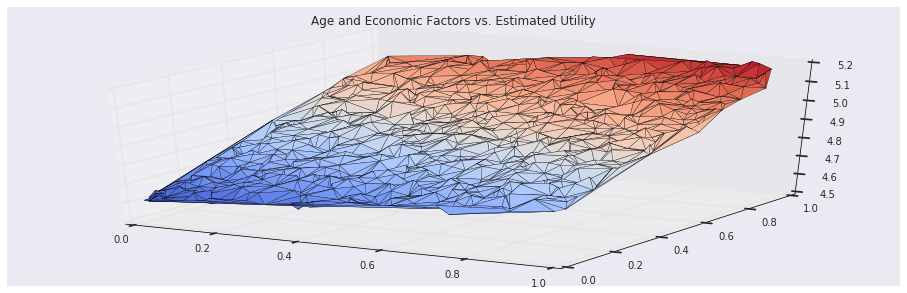
plt.gca(projection='3d').plot_trisurf(states[-1000:, 0], states[-1000:, 1], rewards[-1000:], cmap=cm.coolwarm)
plt.title('Both Factors vs. Reward')
plt.show()Out [9]:
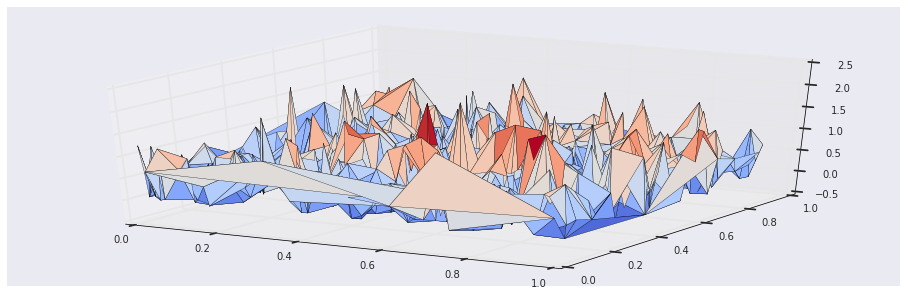
On the other hand, the temporal differences algorithm recovers the true utility associated with the users:
In [10]:
def td_step(curr_weights, Xt, Xt_prev, yt, discount_factor, learning_rate):
utility = curr_weights.dot(numpy.squeeze(Xt))
prev_utility = curr_weights.dot(numpy.squeeze(Xt_prev))
delta = yt + discount_factor*utility - prev_utility
next_weights = curr_weights + learning_rate*delta/(Xt_prev.dot(Xt_prev))*Xt_prev
return utility, next_weights
def td_episode(initial_weights, X, rewards, discount_factor, learning_rate):
utilities = numpy.zeros(len(rewards)-1)
weights = initial_weights
for i in xrange(1, len(rewards)):
utilities[i-1], weights = td_step(weights, X[i, :], X[i-1, :], rewards[i], discount_factor, learning_rate)
return utilities, weights
utilities, weights = td_episode(numpy.zeros(3), states, rewards, 0.9, 0.01)
plt.gca(projection='3d').plot_trisurf(states[-1000:, 0], states[-1000:, 1], utilities[-1000:], cmap=cm.coolwarm)
plt.title('Age and Economic Factors vs. Estimated Utility')
plt.show()Out [10]:
Tomato, Tomahto?
The above are three completely different formulations, motivated by completely different scenarios. But at the end, the essentially same algorithm was derived: it's the same iterative scheme, with almost identical update rules. A clear case of convergent evolution.
The obvious suggestion is: let's just call that algorithm ILT ("Iterative Linear Thingie") and forget all those obscure terms we introduced ("lms", "perceptron", "temporal differences"...).
Should we? The answer depends on the price. Adopting the ILT suggestion will obscure the different perspectives that led to the resulting algorithms, and the price is losing those nuances. This could be perfectly reasonable had those perspectives ran their course, but this is hardly the case: generalizations of this ILT algorithm are utterly unalike when guided by each of those different points of view.
For example, the LMS filter may be generalized to other adaptive filters, such as the Kalman filter which is commonly used in varied situations, from trajectory optimization to econometric smoothing. The perceptron may be generalized to other classification algorithms (e.g. logistic regression, support vector machines and feedforward neural networks). And the temporal differences algorithm is a basis for many algorithms (e.g. Q-learning) in optimal control and autonomous agents, and it can be used to train computers to play backgammon or super-mario better than you can.
None of those generalizations is obvious by considering the ILT alone. But all of them are quite natural as a development of the ideas that led to the ILT in the first place, from the 3 different starting points.
It's worth pointing out that this phenomenon is not unusual, and definitely not limited to machine learning. For example, in elementary calculus an "integral", an "area under the curve" and an "anti-derivative" are pretty much 3 names for the same concept, originated from 3 different perspectives (namely: analytic, geometric and algebraic). But generalizations of this "same concept" take completely different turn when developed from each of those perspective (respectively: differential forms, measures and differential equations).
Literary Coda
Regarding the title, wikipedia says: "Eco has stated that his intention was to find a 'totally neutral title'... [it] 'came to me virtually by chance'".